

Die UB Leipzig hat in ihren Beständen mehr als 7.000 Handschriften in lateinischer Schrift, davon rund 3.000 aus dem Mittelalter; dazu noch über 3.500 Handschriften in anderen Schriftsystemen wie arabisch, persisch, griechisch oder hebräisch – und da sind die 5.000 Papyri und Ostraka noch nicht mitgezählt. Es handelt sich also um einen enormen Fundus an Daten, von dem Forschende weltweit profitieren, den zu erschließen aber einen erheblichen Aufwand bedeutet. Im Bereich Sondersammlungen und am Handschriftenzentrum wird genau diese Erschließungsarbeit geleistet. Was dort aber in der Regel bislang nicht passiert, ist, die Handschriften in Gänze zu transkribieren und einen Text herzustellen, der sowohl von Menschen ohne Spezialkenntnisse als auch von Maschinen gelesen und verarbeitet werden kann.

HTR ist eine Form von
computergestützter Texterkennung
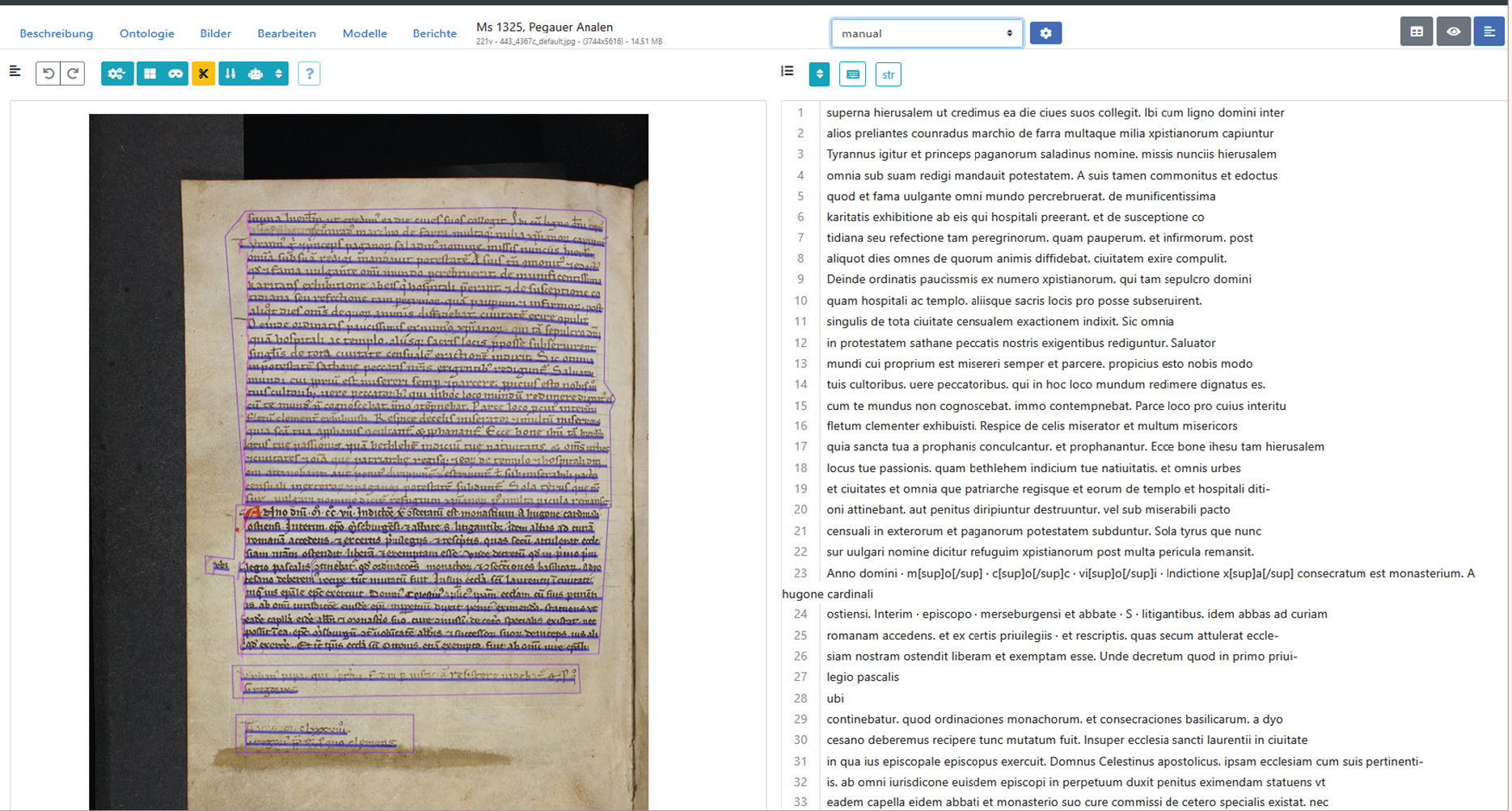
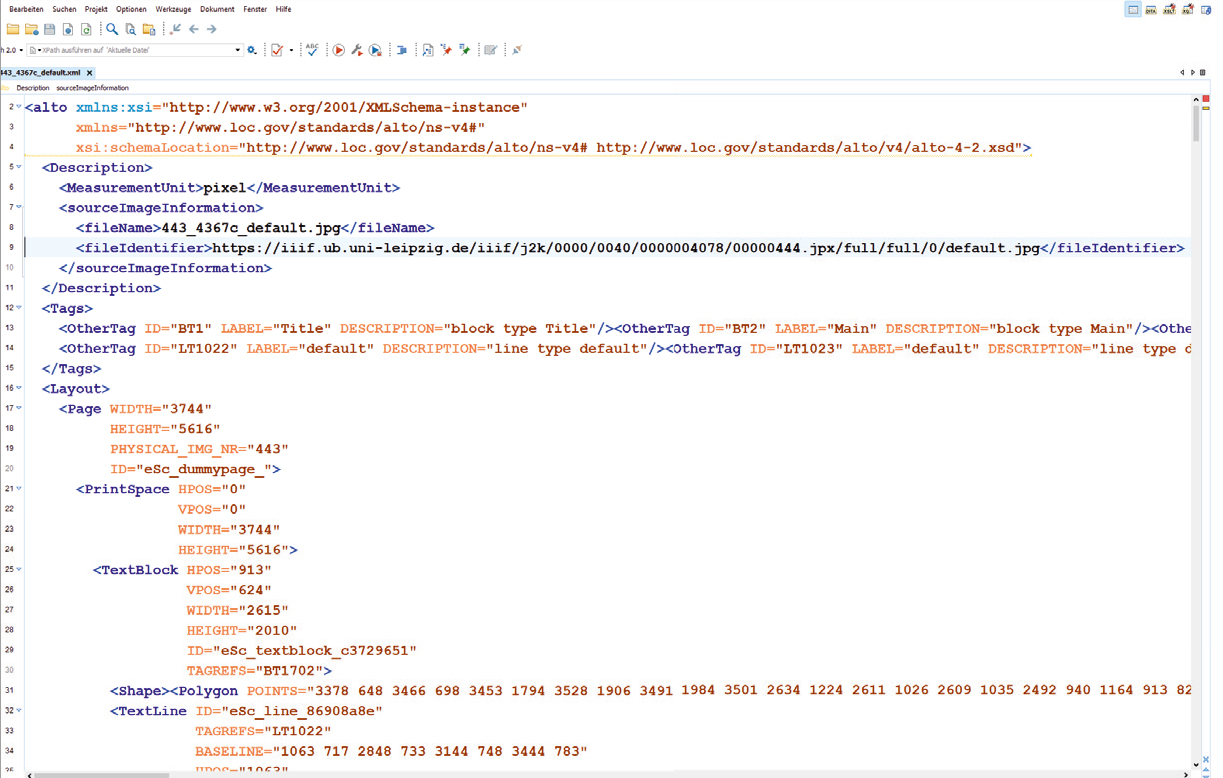
Im vergangenen Jahr gab es mehrere Pilotprojekte an der UB Leipzig, die sich mit Handwritten Text Recognition (HTR) befasst haben. HTR ist eine Form von computergestützter Texterkennung, nur dass hier nicht – wie bei der klassischen Optical Character Recognition (OCR) – einzelne Zeichen erkannt werden, sondern größere Muster wie Buchstabenkombinationen oder ganze Wörter. Das ist der größeren Varianz der Zeichen in einem handschriftlichen Text gegenüber einem gedruckten Text geschuldet.
In einem am Handschriftenzentrum angesiedelten Projekt wurden die Funktionen und Potentiale verschiedener HTR-Programme geprüft und mit den Anforderungen und Bedarfen an der UB Leipzig verglichen. An der Schnittstelle von Sonderbeständen und Digital Humanities wurde eine neue Mitarbeiterstelle besetzt, die mit der Integration von HTR in den Digitalisierungsworkflow befasst ist.
Potentielle
Anwendungsfälle
Dabei ist es nicht nur das Ziel, die digitalisierten Bestände der UB Leipzig mit Volltexten zu versehen und damit Barrieren für eine breite Nutzung dieser Bestände abzubauen. Es geht darüber hinaus auch darum, die Texte als Daten für die maschinelle Weiterverarbeitung bereitzustellen. Potentielle Anwendungsfälle reichen von automatisierten Annotationen, etwa der Verknüpfung von Personen oder Orten mit Normdaten, bis zu Text- und Datamining für linguistische Auswertungen. Mit ausreichend großen Datenmengen könnten sogar Large Language Models (LLMs) für unterschiedliche Sprachstufen trainiert werden, die dann wiederum bei der Arbeit mit den Texten helfen – ChatGPT für das 13. Jahrhundert gewissermaßen.
Die UB Leipzig ist bei diesen Bestrebungen natürlich nicht allein, sondern steht im engen Austausch mit anderen Einrichtungen, die in diesem Bereich Kompetenzen aufgebaut haben. Auch im Rahmen der Handschriftenzentren wird an gemeinsamen Entwicklungen und Standards gearbeitet, um Ressourcen zu bündeln und zukunftsweisende Technologien auf eine breite Basis zu stellen. Im Handschriftenportal sind auch tatsächlich schon die ersten Handschriften mit Volltexten zu finden – wenn auch noch nicht aus den Beständen der UB Leipzig. Das soll sich bald ändern.
- Digitale Sammlungen der Universitätsbibliothek Leipzig
- Der Beitrag erschien zuerst im Tätigkeitsbericht 2024 der Universitätsbibliothek Leipzig.
Ein wirklich spannender Beitrag, danke dafür und für den offenen Einblick. Man mag sich gar nicht vorstellen, wie hoch der Aufwand für die entsprechenden Personen zuvor war, die Dokumente von Hand auszuwerten. Besonders schön finde ich, wie anschaulich gezeigt wird, welches Potenzial „HTR“ für historische Schriften hat und denke, dass man künftig spannende Auswertungen mit den digitalen Schriften anstellen kann.